What is your computer doing?
Over four years ago one of our clients from IPS came to us with a cyber security problem. We were asked to take their task not as a symptom to alleviate, but as a reflection of a deeper problem to solve. While the problem was familiar in computer security, we assigned its root cause to the immense disparity between the amount of information a computer can process and what a human can concentrate on. The solution we developed was to bring to a human scale the world of the computer; to make it possible for machine and humans to collaborate.
The collaboration is essential for solving the computer security problem. The reason is simple: not all the information needed to solve a security problem is in the computer. Take something as simple as a sync tool, the type that sends files from our laptops to a cloud drive such as Dropbox, OneDrive, or Google Drive. The difference between exfiltration and what the sync tool is doing is the account it is uploading to. Deciding if this action is malicious or not is something that will change with circumstances. A security product should make it easy for a person to make that decision.
A computer does billions of operations per second. For scale, we live less than 4 billion seconds. One needs a program to understand those billions of things. In a recent paper we described what became DeepXi, the AI we built that analyzes what is executing on the computer for the last few minutes and then reports back the interesting activities. We defined interesting on a computer security scale: one if it behaves like malicious code, zero if it just sat there waiting for input. (Malicious activities involve changing state outside the CPU, something that requires using a system call, which “simplified” the problem from billions of things per second to hundreds of thousands per second.)
This would be useless if the AI reported back a different activity every minute, but that is not what happens. Like words penned by an author, most activities generated by a computer will have been generated before, with a new one every so often. If we only look at the activities with a score (no matter how small), one Windows laptop will produce about one interesting activity a minute or about 3,000 during a work week. Of those about 150 will be new. But two laptops will not produce 300 new activities. The growth is much smaller because, like words, most activities are common among computers. Between the two they only manage to generate 190 new activities during that week.
The number of different activities generated by one program is a reflection of its complexity. A simple tray program may stick to two for weeks, whereas a program as complex as Chrome (it has over 15 million lines of code) performs 60 of these activities in 12 weeks. They correspond, roughly, to rendering an HTML page, animating with CSS, writing a cookie to disk, and so on. When Firefox and Chrome use the same Windows codec, DeepXi will identify it as the same activity. Chrome and Firefox share many activities, but rarely do Chrome and Word.
The number of distinct words among different written corpora all follow the same growth rule known as Heaps’ Law. Distinct activities also accumulate with the same $c k^\alpha$ curve
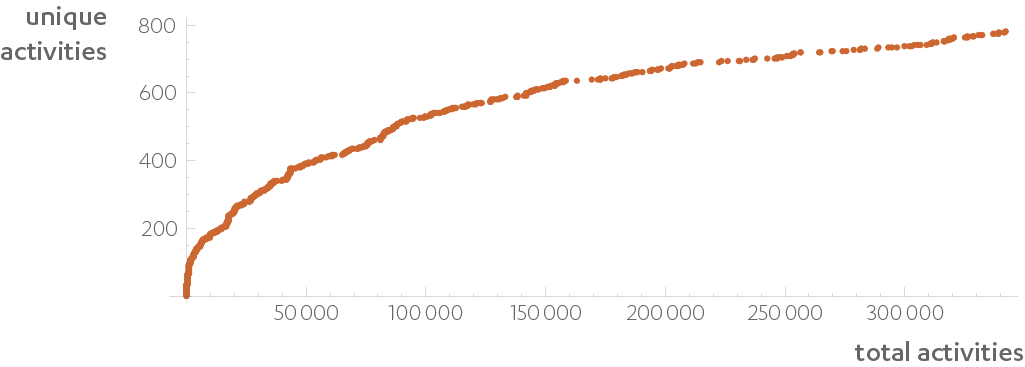
Now imagine a stream of these activities all scored from zero to one. Building a threat hunting process becomes simple. A high scoring activity can be used directly or in conjunction with other tools to gather more context. The activities can be classified so well, that in one week the monitoring of $k$ computers would only produce
false alerts (see section 3 of the paper). Try the formula: 2000 endpoints, 3 false alerts in one week among all of the machines; 20,000 endpoints, 7 false alerts. To that number we need to add the real alerts, but those tend to be small, bringing the problem back to a human scale.